Tutorial 11. Logic and probability
Exercise sheet
Coin flips
Suppose you’re flipping two coins consecutively. You may assume that the outcome of the two coin-flips are independent of each other.
-
Describe the outcome space Ω of the random experiment.
-
Assign probability mass distributions over Ω which correspond to a) a fair coin-flip, where all outcomes are equally likely, and b) an unfair coin-flip where the outcome heads on either flip (the first or second) is twice as likely as tails.
-
Calculate the probabilities of the following events under each of the two distributions:
-
at least one flip is heads
-
both flips are tails
-
the first flip is heads or the second is tails
-
none of the two flips is heads.
-
Solution
-
There are different ways of setting this up, but a straight-forward way is to model the basic outcomes as pairs [x,y], where
x,yare the outcomes of the first and second flip respectively ( {H,T}
{H,T}Hbeing heads, andTbeing tails). That is:Ω = { [H,H], [H,T], [T,H], [T,T]} -
Here are the two distributions, which I call
p₁andp₂:-
p₁([H,H]) = p₁([H,T]) = p₁([T,H]) = p₁([T,T]) = 1/4 -
p₂([H,H]) = 4/9,p₂([H,T]) = 2/9,p₂([T,H]) = 2/9,p₂([T,T]) = 1/9
For
p₁, it should be pretty clear how to arrive at these values: each outcome is equally likely and there are four outcomes, so they must all have probability1/4.For
p₂, one way you can arrive at the values is to treat heads and tails as independent events and the pair as their conjunction. That is we assignH = 2/3andT = 1/3to satisfy the constraint, and then calculate[H,T] = 2/3 x 1/3 = 2/9, etc. -
-
First, let’s translate the events into set representations:
-
“At least one flip is heads” becomes
{[H,H], [H,T], [T,H]} -
“Both flips are tails” becomes
{[T,T]} -
“The first flip is heads or the second is tails” becomes
{[H,T], [H,H], [T,T]} -
“None of the two flips is heads” becomes
{[T,T]}.
For the probabilities of these events under the distributions, we simply add up the weights of the events:
-
Pr₁({[H,H], [H,T], [T,H]}) = p₁([H,H]) + p₁([H,T]) + p₁([T,H]) = 1/4 + 1/4 + 1/4 = 3/4 -
Pr₂({[H,H], [H,T], [T,H]}) = p₂([H,H]) + p₂([H,T]) + p₂([T,H]) = 4/9 + 2/9 + 2/9 = 8/9 -
Pr₁({[T,T]}) = p₁([T,T]) = 1/4 -
Pr₂({[T,T]}) = p₂([T,T]) = 1/9 -
Pr₁({[H,T], [H,H], [T,T]}) = p₁([H,T]) + p₁([H,H]) + p₁([T,T]) = 1/4 + 1/4 + 1/4 = 3/4 -
Pr₂({[H,T], [H,H], [T,T]}) = p₂([H,T]) + p₂([H,H]) + p₂([T,T]) = 2/9 + 4/9 + 1/9 = 7/9
-
Law of total probability
The law of total probability states that for every A,B and every probability Pr, we have:
Pr(A) = Pr(A | B)Pr(B) + Pr(A |
 B)Pr(
B)
B)Pr(
B)
Derive this law from the Kolmogorov axioms. You may use the following facts without further proof:
-
If two formulas are logically equivalent, then they have the same probability. That is, if
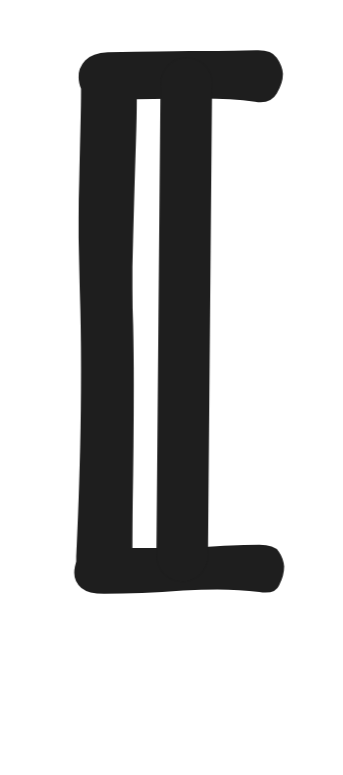 A
A
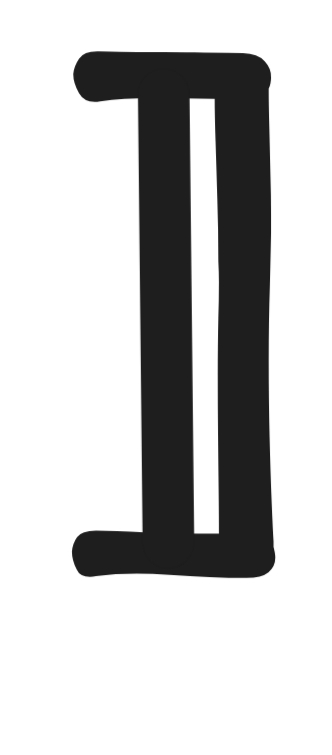 =
B
=
B
Pr(A) = Pr(B). -
Ais logically equivalent to(A B)
B)
 (A
B)
(A
B) -
The conjunction rule
Pr(A
B) = Pr(A | B)Pr(B)
Solution
We start with the trivial identity:
Pr(A) = Pr(A)
Since A is equivalent to (A
,
we can infer:
B)
(A
B)
Pr(A) = Pr((A
B)
(A
B))
We observe that A
and
B)A
are logically
incompatible, that is
B
. Thus: (Pr((A
B)
(A
B)))
(Pr((A
B)
(A
B)))
Pr((A
B)
(A
B)) = Pr((A
B) + (A
B))
So, we arrive at:
Pr(A) = Pr((A
B) + (A
B))
Replacing the conjunctive probabilities using the conjunction rule, we get:
Pr(A) = Pr(A | B)Pr(B) + Pr(A |
B)Pr(
B)
Deductive and inductive inference
Show that if A
B, then A
 B. That is: every
deductively valid inference is also inductively valid. You may use the fact
that if A
B, then A
B is logically equivalent to
A.
B. That is: every
deductively valid inference is also inductively valid. You may use the fact
that if A
B, then A
B is logically equivalent to
A.
Solution
Suppose that A
. For
BA
to be the case, we need
that
BPr(B | A) ≥ Pr(B). Unfolding the definition of conditional probability,
we get:
Pr(B | A) = Pr(B
A)/Pr(A)
But since A
, we have that
BPr(B
. But that
means that:
A) = Pr(A)
Pr(B | A) = Pr(A)/Pr(A) = 1
But since all probabilities are less than 1, it follows that Pr(B | A) ≥ Pr(A).
Base-rate fallacy
The base-rate fallacy is about a common probabilistic fallacy involving conditional probabilities, which has to do with common overestimation of probabilities given information about conditional probabilities.
A simple example concerns diagnostic tests for rare diseases. Suppose that a certain disease has a prevalence of 1% in the population. This is already quite high, most “serious” infectious diseases have a way lower prevalence in the general population.
Now suppose that we have a test for the disease, which is 90% accurate in the following sense:
-
If you have the disease, the test is positive with 0.90 probability. This is called the test sensitivity .
-
If you don’t have the disease, the test is negative with 0.90 probability. This is called the test specificity .
Note that test sensitivity and specificity can differ, but we assume both are the same for simplicity.
-
Express the above information as a probability assignment for the propositional variables
HasDiseaseandTestPositive.Hint: You can estimate the unconditional probability of the person having the disease as the prevalence of the disease in the population.
-
Suppose we’re administering the test to a randomly selected person from the population. The test results positive. What is the probability that the person has the disease given this outcome? What do you notice?
Hints:
-
Use Bayes rule applied to determine
Pr(HasDisease | TestPositive) -
You can calculate the marginal probability
Pr(TestPositive)using the law of total probability from information you already have. -
You need to use that
Pr(and
HasDisease) = 1 - Pr(HasDisease)Pr(
HasDisease |
TestPositive) = 1 - Pr(HasDisease |
TestPositive)
-
-
When you have a positive result, you can re-set the probability of
P(HasDisease)toPr(HasDisease | TestPositive). This is called Bayesian updating . Suppose that there’s a treatment for the rare disease, which has adverse side-effects if you give it to somebody who doesn’t have the disease. So we only want to give the medicine to a patient where we’re more certain than not that they have the disease. How many times do you need to get a positive result before you should administer the medicine if you apply Bayesian updating after each positive result.
Solution
-
Here’s the relevant probabilities:
Pr(HasDisease) = 0.01Pr(TestPositive | HasDisease) = 0.9Pr(¬TestPositive | ¬HasDisease) = 0.9
-
According to Bayes formula
Pr(HasDisease | TestPositive)=[Pr(HasDisease) x Pr(TestPositive | HasDisease) ] / Pr(TestPositive)We have
Pr(HasDisease)andPr(TestPositive | HasDisease), but we need to figure outPr(TestPositive).For this, we use the law of total probability. Apply it to
TestPositiveasAandHasDiseaseasBgives us:Pr(TestPositive)=Pr(TestPositive| HasDiesease)Pr(HasDisease)+Pr(TestPositive | ¬HasDisease)Pr(¬HasDisease)We have
Pr(TestPositive| HasDiesease)andPr(HasDisease)given. To obtainPr(TestPositive | ¬HasDisease)andPr(¬HasDisease), we apply the negation laws:Pr(TestPositive | ¬HasDisease) = 1 - Pr(¬TestPositive | ¬HasDisease)Pr(¬HasDisease) = 1 - Pr(HasDisease)Now we have all the relevant values and can calculate:
Pr(¬HasDisease) = 1 - Pr(HasDisease) = 1 - 0.01 = 0.99Pr(TestPositive | ¬HasDisease) = 1 - Pr(¬TestPositive | ¬HasDisease)= 1 - 0.9 = 0.1Pr(TestPositive | ¬HasDisease)Pr(¬HasDisease) = 0.99 x 0.1 = 0.099So:
Pr(TestPositive)=Pr(TestPositive| HasDiesease)Pr(HasDisease)+Pr(TestPositive | ¬HasDisease)Pr(¬HasDisease)=(0.9 x 0.01) + 0.099 = 0.108Now for the final probabilities:
Pr(HasDisease | TestPositive)=[Pr(HasDisease) x Pr(TestPositive | HasDisease) ] / Pr(TestPositive)=(0.01 x 0.9) / 0.108 = 0.009 / 0.108 = 0.083...In other words, a random person testing positive, given this setup, gives us a probability of around 8% of them having the disease—even if the test is 90% reliable. This is because the prior probability of the person having the disease—the so-called base-rate—is very low.
Note that it’s important here that the person was chosen randomly. If there is additional information, such as them showing symptoms, the prior of them having the disease would be different.
-
If we re-set the probabilities using Bayesian updating, we now have:
Pr(Disease) = 0.083...This affects the value of
Pr(TestPositive), which we’ve calculated usingPr(Disease).We now get:
Pr(¬HasDisease) = 1 - Pr(HasDisease) = 1 - 0.083.. = 0.916...Pr(TestPositive | ¬HasDisease)Pr(¬HasDisease) = 0.1 x 0.916... = 0.0916...Similarly, we get for the other summand:
Pr(TestPositive | HasDisease)Pr(HasDisease) = 0.9 x 0.083.. = 0.0749...So, we now have for
Pr(TestPositive)that:Pr(TestPositive) = 0.0749... + 0.0916... = 0.16...Pr(HasDisease | TestPositive)=[Pr(HasDisease) x Pr(TestPositive | HasDisease) ] / Pr(TestPositive)=(0.083 x 0.9) / 0.16... = 0.0747 / 0.16... ≈ 0.47So, we need to do another test. Now we go somewhat quicker:
Pr(Disease) = 0.47Pr(TestPositive | ¬HasDisease)Pr(¬HasDisease) = 0.1 x 0.53 = 0.053Pr(TestPositive | HasDisease)Pr(HasDisease) = 0.9 x 0.46 = 0.414So:
Pr(TestPositive) = 0.467Pr(HasDisease | TestPositive)=[Pr(HasDisease) x Pr(TestPositive | HasDisease) ] / Pr(TestPositive)=(0.47 x 0.9) / 0.467... ≈ 0.9So only after the third positive test in a row, we can infer with 90% confidence that the patient has a disease.